Christoph Adami

Christoph Adami is a computational biologist with a focus on theoretical, experimental and computational Darwinian evolution.
A professor of Microbiology and Molecular Genetics as well as Physics and Astronomy at Michigan State University, he uses mathematics and computation to understand how simple rules can give rise to the most complex systems and behaviours.
Many of my slides contain direct quotes from Mr Adami’s paper.
Resources
What Is Information?
Information is that which allows you* to make predictions with accuracy better than chance.
*You, who possesses the information.
What Is Information?
Information is that which allows you to make predictions with accuracy better than chance.
Okay, but:
- Predictions about what?
- What exactly is “better than chance”?
Predictions of What?

Predictions of the states the system can take on. :)
Coin, 2 states
- heads
- tails
Standard Die, 6 states
- 1 through 6 dots
Weather Condition, 47 on Yahoo Weather
- sunny
- cloudy
- rainy
- snowy
- etc.
Better than Chance?

Probability is the study of chance.
The study of things that might happen or might not happen.
Probability

The probability (p) of an event is always between zero (impossible) and one (certain).
The sum of the probabilities of possible events is always 1.
Flipping a fair coin has two possible outcome events:
- Heads, with a probability of ph
- Tails, with a probability of pt
p = p(h) + p(t) = 0.5 + 0.5 = 1
Resources
Dicing

When rolling a die, the probability of landing on any given side is 1/N.
N being the number of side of the dice.
When rolling a fair six-sided die, each side has a probability of 1/6.
When rolling a fair four-sided die, each side has a probability of 1/4.
Resources
Uncertaintly

How much don’t we know before a coin flip?
Is it two?
How much don’t we know before the role of a 4 sided die?
Is it four?
What are the entropies of these systems?
Logarithmic Bases
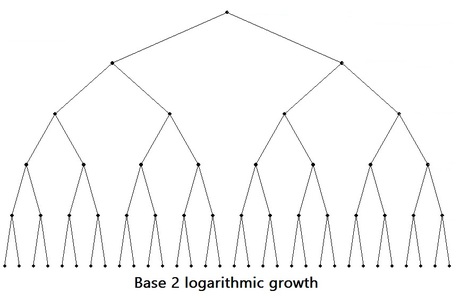
Logarithmic scales show orders of magnitude, but they don’t always have to be orders of 10.
The logarithmic base raised to what power equals the number?
bp = n
logbn = p
| log10 | log2 |
|---|---|
| log101 = 0 | log21 = 0 |
| log1010 = 1 | log22 = 1 |
| log10100 = 2 | log24 = 2 |
| log101000 = 3 | log28 = 3 |
Asking Questions

So why is the uncertainty of a coin flip, log(2)?
When we’re uncertain about something we ask questions!
For base 2 logs, the uncertainty of a system can defined as:
The number of yes/no questions we have to ask to determine the outcome of a system.
Asking Questions

For a coin flip with two states, the entropy is log(2) = 1 bit.
We only need to ask one question to determine the outcome:
- Is it heads?
What about for a four sided die? An eight sided die?
Entropy is logarithmic because decision trees grow logarithmically.
Encoding Entropy
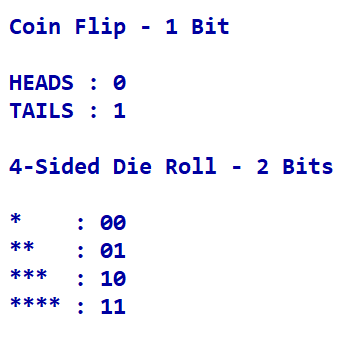
Another way to look at entropy is in terms of encoding or transcribing possible outcomes.
How many bits are required to communicate the outcome of a coin flip?
How about for a 4-sided die?
The Eye of the Beholder

So, what is the entropy of a coin? Is it log(2)?
What if I told you it was infinite?
If a coin has only two sides how can its entropy be infinite?
Well, because entropy is subjective. It depends on what we care about, what we choose to measure.
The Eye of the Beholder
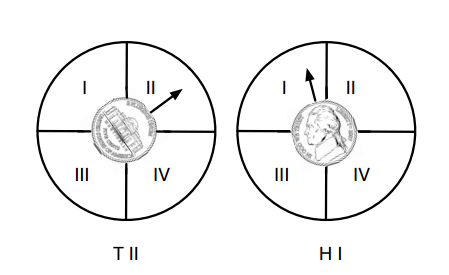
“What if I told you that I’m playing a somewhat different game, one where I’m not just counting whether the coin comes up heads or tails, but am also counting the angle that the face has made with a line that points towards True North. And in my game, I allow four different quadrants”
There are now 8 states. (2 sides times 4 quadrants)
So is the entropy now log(8)? Sure, until I change the game!
What Does it Mean to Have Information

Imagine a urn filled with coloured balls…
Wait, what?
Let’s take two examples in instead:
- Gaining information about a card selected at random.
- Gaining information about a weather system.
Card Tricks
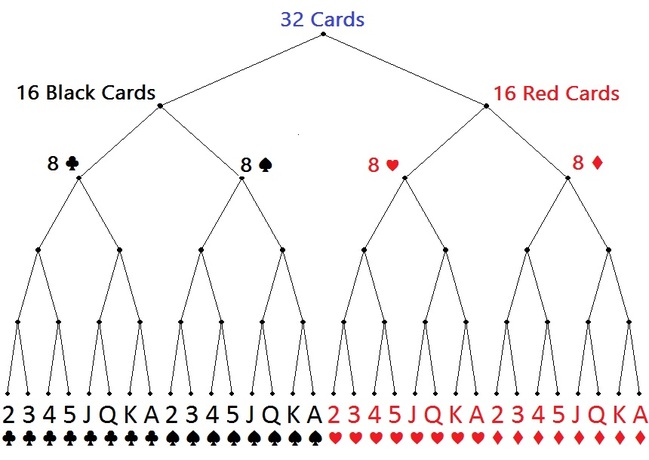
Imagine a deck of 32 cards: Two colours, four suits, 8 cards of each suit.
Pick a Card!
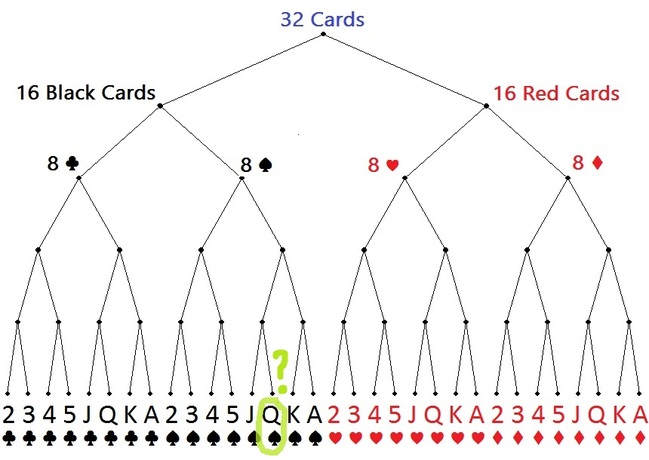
When picking a random card from the deck, what’s the chance it’s the Queen of spades?
The probability is 1/32. The uncertainty is log232, or 5 bits.
It would take 5 bits to describe all the equally possible outcomes.
Said another way, I would need to ask 5 questions to determine the outcome of a randomly selected card.
Gaining Information
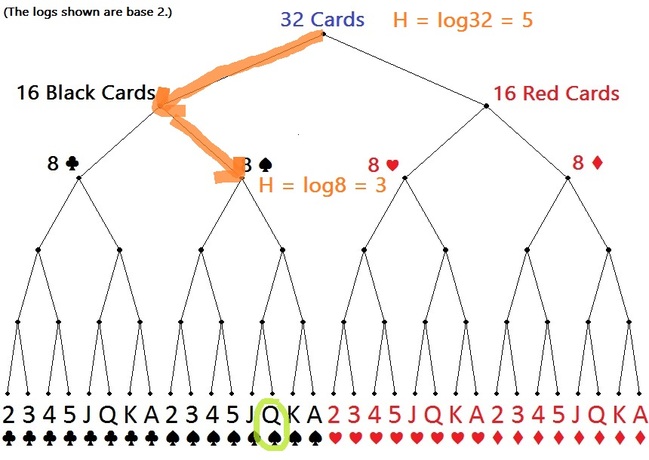
If I told you the card selected is a spade, then the probability that it’s the Queen of Spades goes from 1/32 to 1/8. You’ve gained two bits of information!
Resources
- What is Information Entropy? - “Art of the Problem” Video
The Weather Device

Let’s think about quantifying information in terms of binary communication.
Imagine we have a weather measurement device. It’s a crude device that lumps all weather into four categories:
- Sunny
- Cloudy
- Rainy
- Snowy
Different Entropies
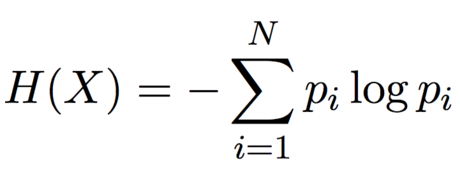
Entropy is maximum when all we know is the number of states:
Hmax = log(N)
When we know the probabilities of the states we get a different entropy H(X).
Information is the delta, the difference between these entropies.
I = Hmax - H(X)
Conditional Probability
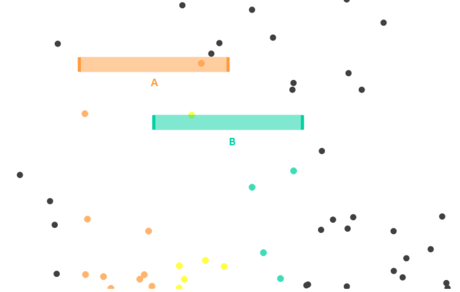
A conditional probability is the probability of an event, given some other event has already occurred.
P(A) = Probability of a ball hitting shelf A
P(B) = Probability of a ball hitting shelf B
P(A|B) = Probability of a ball hitting shelf A given we know that it hit shelf B.
P(A) = 1/3
P(B) = 1/3
P(A|B) = 1/2
Conditional Crashing
| Manoeuvre | Car Crash | Texting |
|---|---|---|
| forward | no | yes |
| right turn | no | no |
| right turn | yes | yes |
| left turn | no | yes |
| reverse | no | no |
| left turn | no | no |
| reverse | yes | yes |
| forward | no | no |
| ... | ... | ... |
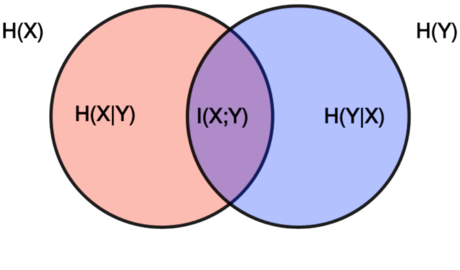
X = Crashing While Driving
H(X) = Uncertainty of Crashing while Driving
WHAT YOU DON'T KNOW about Crashing while driving.
Y = Driving While Texting
H(Y) = Uncertainty of Driving while Texting
H(X|Y) = Uncertainty of Crashing while Driving, Given Texting Status
WHAT REMAINS TO BE KNOWN about Crashing while Driving
GIVEN WHAT YOU KNOW about Driving while Texting.
I(X:Y) = Information Gained About Crashing While Driving
Shared Entropy. Mutual Information.
I(X:Y) = H(X) - H(X|Y)
WHAT YOU DON'T KNOW
minus
WHAT REMAINS TO BE KNOWN GIVEN WHAT YOU KNOW